- Почему Linux-сервер зависает каждые несколько часов
- Быстрые команды, которые решают проблему в 80-90% случаев
- 1. Проверка следов OOM killer в dmesg
- 2. Смотрим текущее состояние памяти и swap
- 3. Быстрый срез самых тяжёлых процессов
- 4. Журнал ядра за текущую загрузку с ошибками
- Проверяем нагрузку системы через Load Average
- Диагностика I/O wait и дисковой подсистемы
- Как понять какой процесс убивает OOM killer
- Как работает OOM killer и почему он так бесит
- Диагностика памяти и swap это корень 70–80% зависаний
- Шаг 1. Создаём файл swap
- Шаг 2. Ограничиваем доступ
- Шаг 3. Форматируем swap
- Шаг 4. Активируем swap
- Шаг 5. Делаем swap постоянным
- Уменьшаем агрессивность свопинга
- Использование zRAM
- Перегрузка CPU это вторая по популярности причина
- Пошаговый чек-лист диагностики
- Практические способы стабилизации сервера
- Частые ошибки администраторов
- FAQ по зависаниям Linux-сервера
- Вывод
Если ваш Linux-сервер (VPS или выделенный) стабильно зависает каждые 2-8 часов, то в 80-90% случаев виновата нехватка оперативной памяти + срабатывание OOM killer. Система начинает убивать процессы, swap забивается, CPU улетает в 100% и привет, полная неотзывчивость по SSH и в сети.
Вот четыре команды, которые в большинстве случаев либо сразу показывают проблему, либо дают чёткое направление для диагностики (проверено на Ubuntu 24.04, Debian 12, AlmaLinux 9 в 2026 году):
dmesg | grep -i -E "oom|killed"
free -h
swapon --show
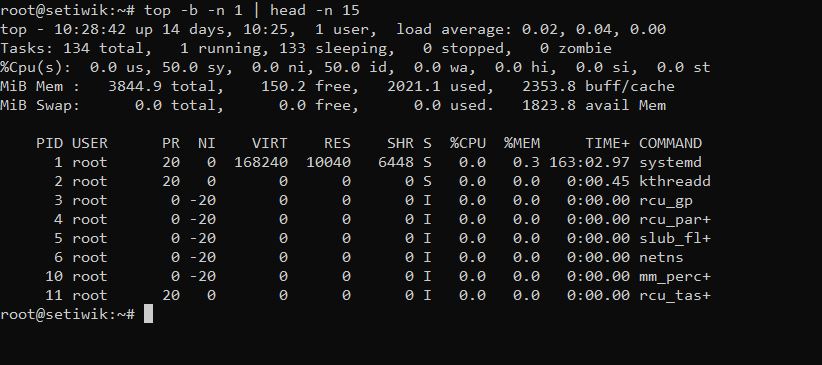
top -b -n 1 | head -n 15
Что делает каждая команда:
- dmesg показывает сообщения ядра Linux
- free -h показывает использование оперативной памяти
- swapon –show показывает активные swap-разделы
- top показывает нагрузку CPU и процессы
А теперь разберём всё по-человечески, потому что зависания сервера это классика, через которую прошёл почти каждый админ.
Почему Linux-сервер зависает каждые несколько часов
Чаще всего картина такая:
- заканчивается свободная RAM
- система начинает активно свопить на диск
- дисковая подсистема тормозит (особенно на дешёвых VPS с HDD или перегруженным NVMe)
- CPU уходит в 100% из-за тысяч page fault
- ядро запускает OOM killer и убивает процессы
- сервер на несколько минут становится полностью неотзывчивым
Иногда после убийства «плохого» процесса всё отмирает и работает дальше. Иногда же система уходит в глубокий ступор на 5-40 минут. А давай честно, кто из нас не получал грозные сообщения «сервер лёг, а завтра утром заказчик будет орать».
Было у меня на одном VPS с 1 ГБ RAM в 2024 году. Ночью каждые 3 или 4 часа полная тишина. Оказалось, что cron-скрипт импорта товаров в 3:17 каждую ночь съедал всю память, OOM убивал php-fpm потом nginx потом mysql и привет. Добавили swap и ограничили память php-fpm и не поверите проблема исчезла за одну ночь.

Быстрые команды, которые решают проблему в 80-90% случаев
1. Проверка следов OOM killer в dmesg
dmesg | grep -i -E "oom|killed|out of memory" --color
Если видите что-то вроде:
[12345.678] Out of memory: Killed process 23456 (php-fpm)
то виновник найден на 90%. Это самая частая картина на веб-серверах.
2. Смотрим текущее состояние памяти и swap
free -h
Команда показывает:
- общий объём RAM
- используемую память
- свободную память
- буферы и кеш
- swap
Пример нормального вывода:

Теперь проверяем swap:
swapon --show
Если Swap равен 0B это серьёзный сигнал. Сервер работает без страховки памяти.
3. Быстрый срез самых тяжёлых процессов
top -b -n 1 | head -n 20
Пояснение параметров:
- -b пакетный режим для вывода в терминал
- -n 1 один запуск команды
Или ещё удобнее:
htop
Сортировка по %MEM или %CPU сразу покажет виновника.
4. Журнал ядра за текущую загрузку с ошибками
journalctl -k -p err -b | grep -i -E "oom|memory|killed"
На системах с systemd это часто информативнее чем простой dmesg.
Проверяем нагрузку системы через Load Average
Ещё одна важная команда:
uptime
Пример вывода:
load average: 0.45 0.60 0.70 Три числа означают среднюю нагрузку системы за:
- 1 минуту
- 5 минут
- 15 минут
Если сервер имеет 2 CPU ядра, то load average выше 2 означает перегрузку.
Диагностика I/O wait и дисковой подсистемы
Иногда сервер зависает не из-за CPU или RAM, а из-за медленного диска.
Проверить это можно командой:
vmstat 1 10
Если колонка wa постоянно высокая, значит система ждёт диск.
Также полезна команда:
iostat -x 1 5
Она показывает задержки дисковой подсистемы.
Как понять какой процесс убивает OOM killer
Иногда сообщения dmesg очищаются после перезагрузки. Тогда полезно проверить системные логи.
grep -i "killed process" /var/log/syslog* 2>/dev/null | tail -n 20
Эта команда ищет последние процессы, которые были убиты OOM killer.
Чаще всего жертвами становятся:
- php-fpm
- mysql или mariadb
- node
- java
- docker контейнеры
Как работает OOM killer и почему он так бесит
OOM killer это аварийный механизм ядра. Когда свободной памяти почти не остаётся, ядро вынуждено завершать процессы.
Выбор процесса происходит по специальному алгоритму:
- объём используемой памяти
- приоритет процесса
- oom_score_adj
На современных системах также используется systemd-oomd.
Проверить его логи можно так:
journalctl -u systemd-oomd
Диагностика памяти и swap это корень 70–80% зависаний
Если swap отключён или слишком маленький, система почти гарантированно будет зависать при пиковых нагрузках.
Создаём swap файл.
Шаг 1. Создаём файл swap
sudo fallocate -l 4G /swapfile
Команда создаёт файл размером 4 ГБ.
Шаг 2. Ограничиваем доступ
sudo chmod 600 /swapfile
Эта команда делает файл доступным только для root.
Шаг 3. Форматируем swap
sudo mkswap /swapfile
Команда превращает файл в swap-раздел.
Шаг 4. Активируем swap
sudo swapon /swapfile
Swap начинает работать сразу.
Шаг 5. Делаем swap постоянным
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
Теперь swap будет подключаться после перезагрузки.
Уменьшаем агрессивность свопинга
Применяем сразу:
sudo sysctl vm.swappiness=10
Делаем настройку постоянной:
echo 'vm.swappiness=10' | sudo tee -a /etc/sysctl.conf
Использование zRAM
Для систем с небольшой памятью можно включить сжатый swap в RAM.
sudo apt update
sudo apt install zram-config
Перегрузка CPU это вторая по популярности причина
Когда памяти не хватает, система генерирует тысячи page fault, и CPU может быть загружен на 100%.
Найти прожорливые процессы можно так:
ps aux --sort=-%cpu | head -15
ps aux --sort=-%mem | head -15
Пошаговый чек-лист диагностики
free -hиswapon --showпроверяем памятьdmesg | grep -i oomпроверяем убийства процессовtopилиhtopищем прожорливые процессыjournalctl -u systemd-oomdпроверяем userspace OOMvmstat 1 10смотрим swap и I/O waituptimeпроверяем load average
Практические способы стабилизации сервера
- добавить RAM
- ограничить php-fpm
- ограничить MySQL или MariaDB
- установить лимиты памяти в systemd
- использовать earlyoom
- установить мониторинг
Для мониторинга отлично подходят:
- Netdata
- Glances
- Prometheus + Grafana
Частые ошибки администраторов
| Ошибка | Последствия | Решение |
|---|---|---|
| нет swap | сервер зависает | создать swap файл |
| слишком большой swap на HDD | долгие тормоза | использовать SSD или zRAM |
| vm.swappiness 60 | слишком ранний swap | уменьшить до 10 |
| неограниченный php-fpm | скрипты съедают память | ограничить процессы |
| нет мониторинга | проблемы появляются внезапно | установить Netdata |
FAQ по зависаниям Linux-сервера
Почему сервер зависает ночью?
Как узнать какой процесс использует память?
Что делать если swap постоянно заполнен?
OOM killer это плохо?
Почему сервер зависает но потом оживает?
Может ли виноват диск?
Как проверить нагрузку сервера и время работы сервера?
Что означает load average?
Поможет ли перезагрузка?
Как предотвратить зависания?
Какой размер swap оптимален в 2026 году?
Вывод
Linux сервер который зависает каждые несколько часов почти всегда страдает от нехватки памяти.
Основные причины:
- OOM killer
- отсутствие swap
- перегрузка CPU
В большинстве случаев проблема решается за 10–15 минут. Нужно просто проверить логи на OOM, убедиться в наличии swap, посмотреть top или htop и ограничить самые прожорливые процессы.
В 2025–2026 годах на большинстве веб серверов с WordPress, Laravel или Next.js достаточно добавить swap 4 ГБ, уменьшить vm.swappiness до 10 и настроить лимиты php-fpm.
А у вас какие причины самых неприятных зависаний были в последнее время. Пишите в комментариях обсудим.
Понравилась статья?
Помогите Setiwik.ru создавать больше глубоких обзоров и новостей. Один клик и ваш вклад помогает держать серверы включёнными и авторов мотивированными!
Поддержать проектСпасибо, что вы с нами!